Exchange 2007 Replication: Exchange 2007 has different types of High Availability features, I would like to discuss about how the data been replicated to various exchange server to provide High Availability, we know the LCR, CCR, SCR and SCC features from Exchange 2007, Will see how this features replicate the Exchange database to other Disk or other exchange server
LCR (Local Continuous Replication) and CCR (Cluster Continuous Replication) uses exchange built-in asynchronous log shipping and log replay technology to replicate database, actually speaking it will replicate Transaction log files not the database
SCR (Single Copy Clusters) will not replicate the Exchange database or log files because it uses the common storage to provide fault tolerance like a native Exchange cluster
SCC (Standby Continuous Replication): SCC is same like CCR & LCR and it uses the same Replication technology
Asynchronous log shipping and log replay: Exchange server was designed to write all transactions to transaction log files first and commit the changes to the databases from the transaction log files, changes are not directly written in to exchange database for better performance and checkpoint file know which part of transaction log are committed to the exchange database, transaction log files size is 1 megabyte (MB) in Exchange 2007
Transaction log file size in Exchange 2003 is 5 MB, it’s reduced to 1 MB in Exchange 2007 to reduce data loss, and how it will prevent the data loss? LCR and CCR use the transaction log files to replicate the changed data to the other disk in LCR, to other exchange server in CCR, copies the transaction log files from active note to passive node, replication mechanism is asynchronous to the online database
Replication is asynchronous Logs are not copied from active node to passive node, until they are closed and no longer used by the Mailbox server in active node, hence the passive node usually does not have a copy of every log file that exists on the active node (except a scheduled outage initiated by admin) because of reduced log file size (1 MB log file size) passive node has the most recent data and data loss is controlled
Transport dumpster can be used to recover the mails from the log files that are currently used by the Mailbox server in active node to reduce the mail loss from the asynchronous replication, Hub Transport servers maintain a queue of recently delivered mail, When a failover is experienced then clustered mailbox server automatically requests every Hub Transport server in the Active Directory site to resubmit mail from the transport dumpster queue, this queue has been used while the time of failover
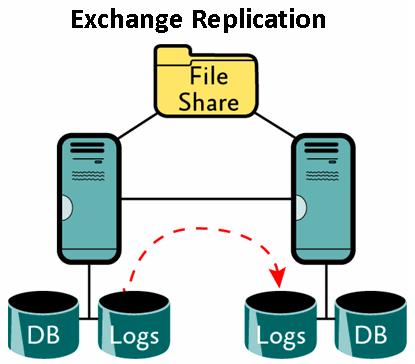
How the transaction log files are replicating to passive node: The transaction log files folder on the active node is shared using standard Windows file share. The GUID (globally unique identifier) for the storage group is used for the share name, and a dollar sign ($) is added to the end of the share. The Microsoft Exchange Replication service on the passive node connects to the share on the active node and copies (pulls) the log files using the SMB (Server Message Block) protocol. The passive node then verifies the log file and replays it into the copy of the database on the passive node.